1) select한 열만 복사해서 새로운 파일 생성
CREATE TABLE members_backup_all(SELECT * FROM members);
2) 테이블 데이터 삽입 키 중복 시 데이터 수정
INSERT INTO members(mbr_id, mbr_nm, mbr_addr, mbr_daddr, mbr_zip, mbr_email, mbr_telno, mbr_reg_date)
VALUES ('id001', '홍01', '전북 전주시 기린대로 499', '3층 한국스마트정보교육원', '54888', '홍01@ksmart.or.kr', '010-0001-0001', curdate())
ON DUPLICATE KEY UPDATE mbr_nm = '홍001', mbr_telno = '010-0010-0001';
3) 테이블 데이터 삽입 키 중복 시 삽입 데이터 무시
INSERT IGNORE INTO members(mbr_id, mbr_nm, mbr_addr, mbr_daddr, mbr_zip, mbr_email, mbr_telno, mbr_reg_date)
VALUES
('id001', '홍01', '전북 전주시 기린대로 499', '3층 한국스마트정보교육원', '54888', '홍01@ksmart.or.kr', '010-0001-0001', CURDATE()),
('id010', '홍10', '전북 전주시 기린대로 499', '3층 한국스마트정보교육원', '54888', '홍10@ksmart.or.kr', '010-0010-0010', CURDATE());
4) 테이블 데이터 조회 정렬
SELECT m.mbr_id, m.mbr_nm, m.mbr_telno AS '연락처' FROM members m
WHERE m.mbr_zip = '54888' ORDER BY 연락처 ASC, mbr_id DESC;
5) 테이블 데이터 조회 출력 갯수 제한(0번째부터 시작) ex) limit 0,5 -> 0부터 다섯개까지 출력
SELECT * FROM members LIMIT 0, 5;
6) 테이블 데이터 조회 시 행 중복 제거
SELECT DISTINCT mbr_zip FROM members;
데이터 모델링
1) 데이터 모델링 : 복잡한 현실 세계에 존재하는 데이터를 단순화 시켜 표현해 컴퓨터 세계의 데이터베이스로 옮기는 변환 작업. 업무에 필요로 하는 데이터를 파악하여 데이터베이스를 구축하기 위한 분석/설계의 과정
1-1) 데이터 모델링의 특징
- 추상화(Abstraction) : 현실 세계를 일정한 형식에 맞추어 간략하게 표현
- 단순화(Simple) : 복잡한 현실세계를 약속된 규약에 의해 제한된 표기법이나 언어로 쉽게 이해할 수 있도록 표현
- 명확성(Clarity) : 명확하게 의미가 해석되어야 하고 한 가지 의미를 가져야 함.
2) 데이터베이스의 개념도
2-1) 개념적 데이터 모델
- 추상화의 수준이 높고 업무 중심적이고 포괄적인 수준
- 조직, 사용자의 데이터 요구사항을 찾고 분석하여 데이터들 간의 관계를 발견하고 이를 표현하기 위해 ER 다이어그램 생성
2-2) 논리적 데이터 모델
- 시스템으로 구축하고자 하는 업무에 대해 KEY, 속성, 관계 등을 정확하게 표현(정규화 진행, DBMS 결정 X)
2-3) 물리적 데이터 모델
- 실제로 데이터베이스에 이식할 수 있도록 성능, 저장 등 물리적인 성격을 고려하여 설계(하드웨어 및 DBMS 결정 O)
3) 개체-관계 모델
3-1) 개체(Entity)
- 업무에 필요하고 유용한 정보를 저장하고 관리하기 위한 집합적인 것
ex) 사람, 장소, 물건, 사건, 개념 등의 명사에 해당
3-2) 속성(Attribute)
- 업무에서 필요로 하는 인스턴스로 관리하고자 하는 의미상 더 이상 분리되지 않는 최소의 데이터 단위
ex) 강사 - 이름, 주소, 생년월일, 계약일자, 전문분야
3-3) 관계(Relationship)
- 엔터티의 인스턴스 사이의 논리적인 연관성으로서 존재의 형태로서나 행위로서 서로에게 연관성이 부여된 상태
ex) 학생(엔터티) - 수강(관계) - 강좌(엔터티) '학생이 강좌를 수강한다.' 의 동사에 해당
3-4) 식별자(Identifiers)
- 하나의 엔터티에 구성되어 있는 여러 개의 속성 중에 엔터티를 대표할 수 있는 속성
ex) 학생 : 학생번호(식별자), 학생이름, 학생주소, 학생연락처



4) 데이터베이스의 키워드
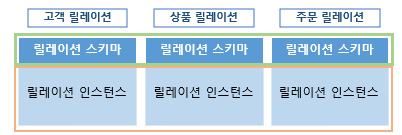
4-1) 데이터베이스 스키마
- 데이터베이스의 전체 구조, 테이블의 구조와 속성에 대한 정보
4-2) 데이터베이스 인스턴스
- 정의된 스키마에 따라 데이터베이스에 실제로 저장된 값
- 데이터베이스를 구성하는 릴레이션 인스턴스의 모음
5) 릴레이션의 특성
1. 튜플의 유일성 : 하나의 릴레이션에는 동일한 튜플이 존재할 수 없다.
2. 튜플의 무순서 : 하나의 릴레이션에서 튜플 사이의 순서는 무의미하다.
3. 속성의 무순서 : 하나의 릴레이션에서 속성 사이의 순서는 무의미하다.
4. 속성의 원자성 : 속성 값은 논리적으로 더 이상 쪼갤 수 없는 원자 값만을 저장한다.
5-1) 릴레이션의 키(식별자)
1. 릴레이션 키(식별자) : 릴레이션에서 튜플들을 유일하게 구별하는 속성 또는 속성들의 집합
5-2) 릴레이션 키의 특성
1. 유일성
- 하나의 키 값으로 하나의 튜플만을 유일하게 식별
- 한 릴레이션에서 모든 튜플은 서로 다른 키 값을 가져야 함
2. 최소성
- 꼭 필요한 최소한의 속성들로만 키를 구성
5-3) 릴레이션 키의 종류
1. 기본키(Primary key) : 후보키 중에서 기본적으로 사용하기 위해 선택한 키
ex) 고객 릴레이션의 기본키 : 고객아이디
2. 후보키(Candidate key) : 유일성과 최소성을 만족하는 속성 또는 속성들의 집합
ex) 고객 릴레이션의 후보키 : 고객아이디, (고객이름, 주소) 등
3. 대체키(Alternate key) : 기본키로 선택되지 못한 후보키
ex) 고객 릴레이션의 대체키: (고객이름, 주소)
4. 슈퍼키(Super key) : 유일성을 만족하는 속성 또는 속성들의 집합
ex) 고객 릴레이션의 슈퍼키: 고객아이디, (고객아이디, 고객이름), (고객이름, 주소) 등
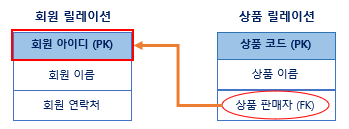
5. 외래키(Foreign key) : 다른 릴레이션의 기본키를 참조하는 속성 또는 속성들의 집합으로 릴레이션들 간의 관계를 표현한다.
참조하는 릴레이션 : 외래키를 가진 릴레이션
참조되는 릴레이션 : 외래키를 참조하는 기본키를 가진 릴레이션
| 분류 | 내용 |
| 키의 특성 | - 유일성 : 한 릴레이션에서 모든 튜플은 서로 다른 키 값을 가져야 함 - 최소성 : 꼭 필요한 최소한의 속성들로만 키를 구성 |
| 키의 종류 | - 기본키 : 후보키 중에서 기본적으로 사용하기 위해 선택한 키 - 후보키 : 유일성과 최소성을 만족하는 속성 또는 속성들의 집합 - 외래키 : 다른 릴레이션의 기본키를 참조하는 속성 또는 속성들의 집합 - 대체키 : 기본키로 선택되지 못한 후보키 - 슈퍼키 : 유일성을 만족하는 속성 또는 속성들의 집합 |
6) 무결성 제약조건
- 무결성 : 데이터가 결함이 없는 상태, 즉 정확하고 유효하게 유지하는 것
- 데이터의 무결성을 보장하고 일관된 상태로 유지하기 위한 규칙
1. 도메인 무결성 제약조건
- 특정 속성의 값이 그 속성이 정의된 도메인에 속한 값이어야 한다는 규칙
- NULL 값은 허용됨 ( NOT NULL 아닌 경우)
- NULL : 공백이나 숫자0과는 전혀 다른 값이며, 조건에 맞는 데이터가 없을 때의 공집합도 아니다. 아직 정의되지 않은 미지의 값, 현재 데이터를 입력하지 못하는 경우의 값을 의미

2. 개체 무결성 제약조건
- 기본키를 구성하는 모든 속성은 NULL 값을 가질 수 없는 규칙

3. 참조 무결성 제약조건
- 외래키는 참조할 수 없는 값을 가질 수 없는 규칙 (But NULL 값을 가진다고 해서 위반한 것은 아님)
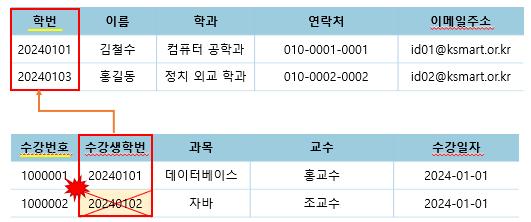
- RESTRICTED : 레코드를 변경 또는 삭제하고자 할 때 해당 레코드를 참조하는 개체가 있다면, 변경 또는 삭제 연산을 취소
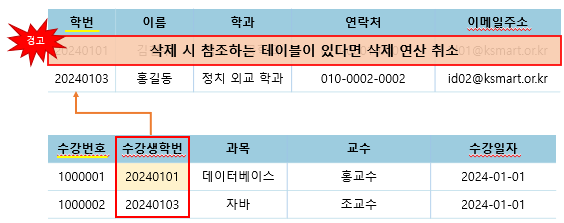
- CASECADE : 레코드를 변경 또는 삭제하면, 해당 레코드를 참조하고 있는 개체도 변경 또는 삭제
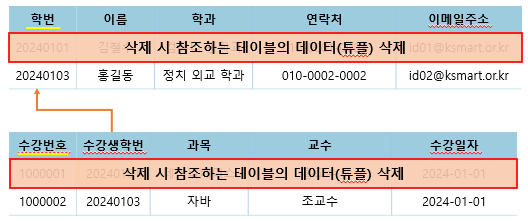
- SETNULL : 레코드를 변경 또는 삭제하면, 해당 레코드를 참조하고 있는 개체의 값을 NULL로 설정

7) 숫자 데이터 타입
| 데이터 형식 | 바이트 수 | 데이터 범위 | 설명 |
| BIT | N/8 | Bit 표현 | |
| TINYINT | 1 | -128~127 | 정수 |
| SMALLINT | 2 | -32,768~32,767 | 정수 |
| MEDIUMINT | 3 | -8,388,608~8,388,607 | 정수 |
| INT | 4 | 약 -21억~+21억 | 정수 |
| BIGINT | 8 | 약 -900경~+900경 | 정수 |
| FLOAT | 4 | -3.40E+38~1.79E-38 | 소수점 7자리 |
| DOUBLE | 8 | -1.22E-308~1.79E+308 | 소수점 15자리 |
| DECIMAL(m, [d]) | 5~17 | 〖-10〗^38+1 ~ 10^38-1 | 최대 65자리 |
8) 날짜 데이터 타입
| 데이터 형식 | 바이트 수 | 설명 |
| DATE | 3 | 날짜: 1001-01-01~9999-12-31까지 저장 날짜형식만 사용 ‘YYYY-MM-DD’ |
| TIME | 3 | 시간: -838:59:59.000000~838:59:59.000000까지 저장 형식: ‘HH:MM:SS’ |
| DATETIME | 8 | 날짜: 1001-01-01 00:00:00~9999-12-31 23:59:59 저장 형식: ‘YYYY-MM-DD HH:MM:SS’ |
| TIMESTAMP | 4 | 날짜: 1970-01-01 00:00:00~2037-12-31 23:59:59 저장 형식: ‘YYYY-MM-DD HH:MM:SS’ Time_zone 시스템 변수와 관련 있으며 UTC 변환 저장 |
| YEAR | 1 | 날짜: 1901~2155까지 저장. 형식: ‘YYYY’ |
9) 문자 데이터 타입
| 데이터 형식 | 바이트 수 | 데이터 범위 |
| CHAR(N) | 1 ~ 255 | 고정길이 문자형 |
| VARCHAR(N) | 1~65535 | 가변길이 문자형 |
| BINARY(N) | 1~255 | 고정길이의 이진 데이터 값 |
| VARBINARY(N) | 1~255 | 가변길이의 이진 데이터 값 |
| TEXT | 1~65535 | N 크기의 TEXT 데이터 값 |
| BLOB | 1~65535 | N 크기의 BLOB 데이터 값 |
| ENUM | 1 또는 2 | 최대 65535개의 열거형 데이터 값 |
| SET | 1, 2, 3, 4, 8 | 최대 64개의 서로 다른 데이터 값 |
10) 비교연산자 논리연산자
1. 비교연산자
| 연산자 | 의미 |
| = | 같다 |
| <> | 다르다 |
| < | 작다 |
| > | 크다 |
| <= | 작거나 같다 |
| >= | 크거나 같다 |
| IS NULL | NULL과 같다 |
| IS NOT NULL | NULL이 아니다 |
2. 논리연산자
| 연산자 | 의미 |
| AND | 모든 조건을 만족해야 검색한다. |
| OR | 여러 조건 중 한 가지만 만족해도 검색한다. |
| NOT | 조건을 만족하지 않는 것만 검색한다. |
11) LIKE 키워드
| 사용예 | 의미 |
| LIKE '데이터%' | 데이터로 시작하는 문자열 (데이터로 시작하기만 하면 길이는 상관없음) |
| LIKE '%데이터' | 데이터로 끝나는 문자열 (데이터로 끝나기만 하면 길이는 상관없음) |
| LIKE '%데이터%' | 데이터가 포함된 문자열 |
| LIKE '데이터___' | 데이터로 시작하는 6자길이의 문자열 |
| LIKE '__데이터%' | 세 번째 글자의 시작이 '데이터'인 문자열 (길이 상관없음) |
'DB' 카테고리의 다른 글
| DB - WITH절(CTE), VIEW(가상테이블), Stored Program, Procedure(프로시저) (0) | 2024.08.12 |
|---|---|
| SQL 실습문제(join) (0) | 2024.08.02 |
| DB - 정규화, 서브쿼리 (0) | 2024.08.02 |
| DB - MySQL (1) | 2024.07.19 |
| DB - 데이터베이스의 개념, 특징, 키워드, DBMS, DDL, DCL, DML (1) | 2024.07.05 |