1) 정규화(Normalization)
- 데이터의 일관성, 최소한의 데이터 중복, 최대한의 데이터 유연성을 위한 방법이며 데이터를 분해하는 과정. 즉 이상현상이 발생하는 릴레이션을 분해하는 과정.
2) 이상현상 (Anomaly)
- 불필요한 데이터 중복으로 인해 릴레이션에 대한 데이터 삽입 수정 삭제 연산을 수행할 때 발생할 수 있는 부작용
- 삽입이상, 갱신(수정)이상, 삭제이상
3) 삽입이상 (Insertion Anomaly)
- 릴레이션에 새 데이터를 삽입하려면 불필요한 데이터도 삽입해야되는 문제
ex) 회원가입시 불필요한 NULL 값을 삽입해야하는 문제

4) 갱신이상 (Update Anomaly)
- 릴레이션의 중복된 튜플 중 일부만 수정하여 데이터가 불일치하게 되는 모순이 발생되는 문제
ex) 회원정보 수정시 등급의 데이터가 불일치되는 일관성 문제 발생

5) 삭제이상 (Deletion Anomaly)
- 릴레이션에서 튜플을 삭제하면 꼭 필요한 데이터까지 손실되는 연쇄 삭제 현상이 발생하는 문제
ex) 회원등급을 삭제시 고객의 정보, 이벤트정보까지 연쇄 삭제되는 이상문제

6) 정규화 (Normalization)
- 이상 현상이 발생하지 않도록, 릴레이션을 관련 잇는 속성들로만 구성하기 위해 릴레이션을 분해하는 과정
- 함수적 종속성을 판단하여 정규화를 수행
7) 함수적 종속성 (Functional Dependency)
- 속성들 간의 관련성
- 함수 종속성을 이용하여, 릴레이션을 연관성이 있는 속성들로만 구성되도록 분해하여 이상현상이 발생하지 않는 릴레이션으로 만들어가는 과정
8) 함수 종속 관계 판단
- 속성 자체의 특성과 의미를 기반으로 함수 종속성을 판단.
- 속성 값은 계속 변할 수 있으므로 현재 릴레이션에 포함된 속성 값만으로 판단하면 안됨.
- 일반적으로 기본키와 후보키는 릴레이션의 다른 모든 속성들을 함수적으로 결정함.
- 기본키나 후보키가 아니어도 다른 속성 값을 유일하게 결정하는 속성은 함수 종속관계에서 결정자가 될 수 있음.

9) 완전 함수 종속
- 릴레이션에서 속성 집합 Y가 속성집합 X에 함수적으로 종속되어 있지만, 속성 집합 X의 전체에 종속되어 있음
- 일반적으로 함수 종속은 완전 함수 종속을 의미함
10) 부분 함수 종속
- 릴레이션에서 속성 집합 Y가 속성 집합 X의 전체가 아닌 일부분에도 함수적으로 종속됨을 의미
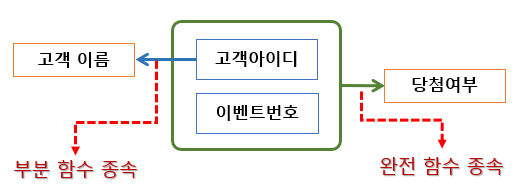
11) 함수 종속 관계 판단시 고려대상이 아닌 경우
- 결정자와 종속자가 같거나, 결정자가 종속자를 포함하는 것처럼 당연한 함수 종속관계는 고려하지 않음
12) 정규형
12-1. 제 1차 정규형 (1NF)
- 릴레이션의 속성값은 원자값(릴레이션의 모든 속성이 더는 분해되지 않는 원자값)
반복 집합이 있는 비정규 릴레이션 -> 반복집합을 제거함 -> 모든 속성값이 원자값으로 구성된 제 1정규형 릴레이션
12-2. 제 2차 정규형 (2NF)
- 기본키에 완전함수 종속(릴레이션이 제 1정규형에 속하고, 기본키가 아닌 모든 속성이 기본키에 완전함수 종속)
모든 속성값이 원자값으로 구성된 제1정규형 릴레이션 -> 부분 함수의 종속성을 제거 -> 모든 속성이 키에 완전함수 종속인 제 2정규형 릴레이션
12-3. 제 3차 정규형 (3NF)
- 이행적 함수종속 제거(릴레이션이 제 2 정규형에 속하고, 기본키가 아닌 모든 속성이 기본키에 이행적 함수 종속되지 않음)
모든 속성이 키에 완전함수 종속인 제2정규형 릴레이션 -> 이행적 함수의 종속성을 제거 -> 키에 대해서 직접으로 함수종속하는 제 3정규형 릴레이션
12-4. 보이스코드 정규형 (BCNF)
- 모든 결정자가 후보키(릴레이션이 제 3 정규형에 속하고, 릴레이션에 존재하는 함수 종속성에서 모든 결정자가 후보키인 릴레이션)
키에 대해서 직접으로 함수종속하는 제 3정규형 릴레이션 -> 후보키 집합에 없는 속성이 결정자가 되는 속성 제거 -> 모든 결정자가 후보키인 BCNF 릴레이션
12-5. 제 4 정규형
- 릴레이션이 보이스/코드 정규형을 만족하면서, 함수 종속이 아닌 다치 종속을 제거한 릴레이션
12-6. 제 5 정규형
- 릴레이션이 제 5 정규형을 만족하면서, 후보키를 통하지 않는 조인 종속을 제거한 릴레이션
* 정규화 시 주의사항
- 모든 릴레이션이 제 5 정규형에 속해야만 바람직한 것은 아님
- 정규화를 많이 거칠 수록 중복은 줄일 수 있으나 성능에 영향을 미침 (조인 연산)
- 일반적으로 제 3 정규형이나 보이스/코드 정규형에 속하도록 릴레이션을 분해하여 데이터 중복을 줄이고 이상 현상을 해결하는 경우가 많음 (실무)

13) 반정규화(역정규화)
- 의도적으로 정규화 원칙을 위배하는 행위로 데이터베이스 성능향상을 위해, 데이터 중복을 허용하고 조인을 줄이는 데이터베이스 성능 향상 방법
- 대상 : 수행 속도가 많이 느린경우, 테이블의 조인 연산을 지나치게 사용하여 데이터를 조회하는 것이 기술적으로 어려운 경우, 테이블에 많은 데이터가 있고, 다량의 범위 혹은 특정 범위를 자주 처리하는 경우
- 장점 : 데이터를 빠르게 조회, 조인을 제거하기 때문에 검색 시간이 최적화
- 단점 : 데이터의 삽입, 삭제, 수정 등 갱신 시 비용이 높아짐, 데이터간의 일관성이 깨질 수 있고, 많은 저장 공간이 필요함 (예시: 테이블의 열이 증가)
14) 서브쿼리(Sub Query)
- 하나의 SQL 문에 포함되어 있는 또 다른 SQL문
- 서브쿼리는 괄호를 감싸서 작성한다
- 서브쿼리는 단일 행 또는 복수 행 비교 시 그에 맞는 연산자와 함께 사용한다
- 서브쿼리에서는 order by를 사용하지 못한다 (데이터 반환이 목적이지 정렬은 의미없다)(MySQL에서는 지원)
- 서브쿼리 사용할 수 있는 곳 : SELECT 절, FROM 절, WHERE 절, HAVING 절, ORDER BY 절, INSERT VALUE 절, UPDATE SET 절
14-1. 스칼라 서브쿼리 : SELECT절에 있는 서브쿼리 (단일행만 반환)
14-2. 인라인 뷰 : FROM절에 있는 서브쿼리
14-3. 서브쿼리 : WHERE절에 있는 서브쿼리
★예제
등록된 상품 중 상품들의 평균 단가보다 높은 상품의 목록을 조회하시오.
-- 서브쿼리 적용 전
-- 평균단가
SELECT
avg(p.prod_untprc) AS '상품평균단가'
FROM
products p;
-- 상품조회
SELECT
p.prod_cd,
p.prod_name,
p.prod_untprc
FROM
products p
WHERE
p.prod_untprc > 181557.6271;
-- 서브쿼리 적용 후
SELECT
p.prod_cd,
p.prod_name,
p.prod_untprc
FROM
products p
WHERE
p.prod_untprc > (
SELECT
avg(p.prod_untprc)
FROM
products p
);
인라인 뷰 - 로그인을 많이한 상위 5명의 사용자 정보를 조회(아이디, 이름, 이메일, 로그인횟수)
SELECT
m.mbr_id,
m.mbr_name,
m.mbr_email,
login_top.login_cnt
FROM
members m
INNER JOIN
(
SELECT
mll.login_id,
COUNT(mll.login_no) AS login_cnt
FROM
members_login_log mll
GROUP BY mll.login_id
ORDER BY login_cnt DESC
LIMIT 5
) login_top
ON m.mbr_id = login_top.login_id;
서브쿼리(WHERE절에 있는 서브쿼리) - 구매한 상품 목록 중 상품을 구매한 수량이 평균 구매 수량보다 높은 상품의 정보를 조회
SELECT
p.prod_cd,
p.prod_name,
oi.order_cnt
FROM
orderitems oi
INNER JOIN
products p
ON oi.order_prod_cd = p.prod_cd
WHERE
oi.order_cnt > (
SELECT
AVG(oi.order_cnt)
FROM
orderitems oi
);
스칼라 서브쿼리(SELECT절에 있는 서브쿼리) - 상품단가 높은 순대로 순위를 조회하시오.
SELECT
(
SELECT
count(p2.prod_cd) + 1
FROM
products p2
WHERE
p2.prod_untprc > p.prod_untprc
) AS `rank`,
p.prod_cd,
p.prod_name,
p.prod_untprc
FROM
products p
ORDER BY `rank` ASC;
14-4. 다중 행 연산자
- 서브쿼리 결과가 다중행일 경우 반드시 다중행 비교연산자로 작성
| 연산자 | 설명 |
| IN | 리턴되는 값 중에서 조건에 해당하는 값이 있으면 참 |
| ANY, SOME | 서브쿼리에 의해 리턴되는 각각의 값과 조건을 비교하여 하나 이상을 만족하면 참 |
| ALL | 값을 서브쿼리에 의해 리턴되는 모든 값과 조건 값을 비교하여 모든 값을 만족해야만 참 |
| EXISTS | 메인 쿼리의 비교 조건이 서브쿼리의 결과 중에서 만족하는 값이 하나라도 존재하면 참 |
★ 예제
다중행 서브쿼리 (IN) - 구매금액중 많이 구매한 인기품목 상위 3개를 구매한 회원을 조회하시오.
SELECT
DISTINCT
m.mbr_id,
m.mbr_email
-- oi.order_prod_cd
FROM
members m
INNER JOIN
orders o
ON m.mbr_id = o.cust_id
INNER JOIN
orderitems oi
ON o.order_no = oi.order_no
WHERE
oi.order_prod_cd IN (
SELECT
popular_product.prod_cd
FROM
(
SELECT
oi.order_prod_cd AS prod_cd ,
SUM(oi.order_cnt) AS order_cnt_total
FROM
orders o
INNER JOIN
orderitems oi
ON o.order_no = oi.order_no
INNER JOIN
products p
ON p.prod_cd = oi.order_prod_cd
GROUP BY oi.order_prod_cd
ORDER BY order_cnt_total DESC
LIMIT 3
) popular_product
);
다중행 서브쿼리(ANY, SOME) -vend_2 거래처가 등록한 스캐너 가격 단가들 중 하나라도 낮은 금액이 있는 상품정보 조회
SELECT
p.vend_cd,
p.prod_name,
p.prod_untprc
FROM
products p
WHERE
p.vend_cd <> 'vend_2'
AND
p.prod_untprc < ANY (
SELECT
p2.prod_untprc
FROM
products p2
WHERE
p2.vend_cd = 'vend_2'
AND
p2.prod_name = '스캐너'
GROUP BY p2.prod_cd
);
다중행 서브쿼리 (ALL) : vend_2 거래처가 등록한 스캐너 가격 단가들 보다 낮은 금액이 있는 상품정보 조회
SELECT
p.vend_cd,
p.prod_name,
p.prod_untprc
FROM
products p
WHERE
p.vend_cd <> 'vend_2'
AND
p.prod_untprc < ALL (
SELECT
p2.prod_untprc
FROM
products p2
WHERE
p2.vend_cd = 'vend_2'
AND
p2.prod_name = '스캐너'
GROUP BY p2.prod_cd
);
다중행 서브쿼리 (EXISTS) - 주소가 '전주시 덕진구 기린대로' 인 지역의 총 구매금액을 조회하시오
SELECT
SUM(oi.order_cnt * p.prod_untprc)
FROM
orders o
INNER JOIN
orderitems oi
ON o.order_no = oi.order_no
INNER JOIN
products p
ON p.prod_cd = oi.order_prod_cd
WHERE
EXISTS (
SELECT
*
FROM
members m
WHERE
m.mbr_id = o.cust_id
AND
m.mbr_addr LIKE '%전주시 덕진구 기린대로%'
);
15. UNION
- 여러 개의 쿼리의 합집합
- 여러 개의 SQL문을 합쳐 쿼리의 결과를 행으로 합치는 것
15-1. UNION VS UNION ALL
- UNION : 여러 개의 쿼리의 중복 값을 제거한 결과
- UNION ALL : 여러 개의 쿼리 결과가 중복이 되더라도 전부 결과에 반영
- 속도 : UNION ALL > UNION
15-2. 규칙
- 각 SELECT의 컬럼의 수가 같아야 한다.
- 컬럼명이 같아야 한다. (같지 않을 경우 alias를 사용하여 같게 만듦)
- 컬럼별 데이터타입이 같아야한다.
- 하나의 ORDER BY만 사용
- SELECT 문(SQL문)의 순서는 상관없다.
'DB' 카테고리의 다른 글
| DB - WITH절(CTE), VIEW(가상테이블), Stored Program, Procedure(프로시저) (0) | 2024.08.12 |
|---|---|
| SQL 실습문제(join) (0) | 2024.08.02 |
| DB - MySQL (1) | 2024.07.19 |
| DB - sql, 데이터 모델링, 키워드, 릴레이션, 키, 무결성 제약조건, 데이터타입, 비교연산자, 논리연산자, like (0) | 2024.07.12 |
| DB - 데이터베이스의 개념, 특징, 키워드, DBMS, DDL, DCL, DML (1) | 2024.07.05 |